Đôi nét về io_uring
io_uring Asynchronous I/O (AIO) framework là một giao diện I/O mới cho Linux, được giới thiệu trên linux kernel version 5.1 (tháng 3 - 2019).
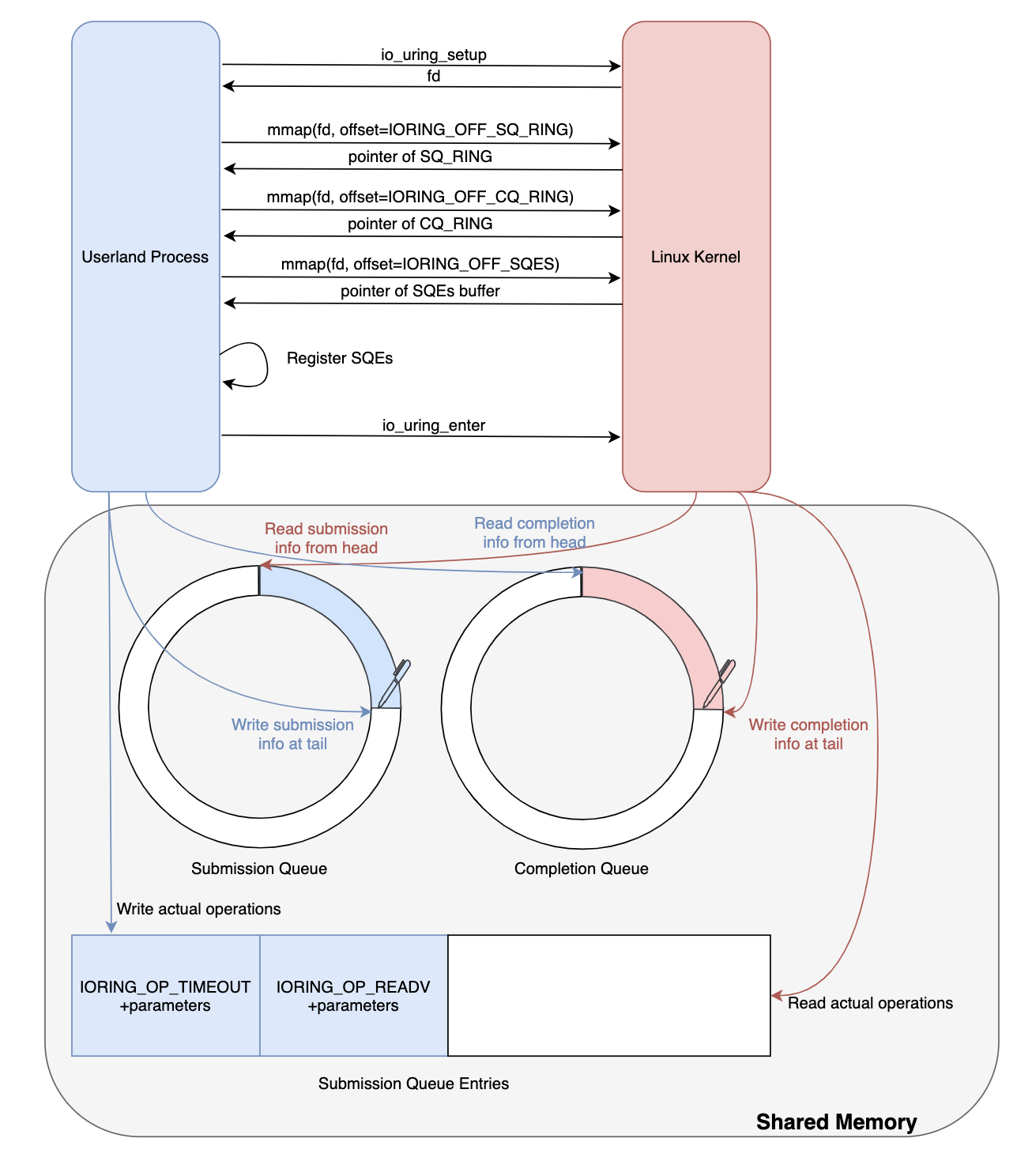
Communication channel
io_uring instancecó 2 vòng,submission queue (SQ)vàcompletion queue (CQ)được chia sẻ giữa kernel và ứng dụng. Những hàng đợi:single producer, single consumercung cấp 1 giao diện ít khóa, và được phối hợp với rào cản bộ nhớ (memory barrier).- Application sẽ tạo một hoặc nhiều SQ entry (SQE) và sẽ cập nhật vào đuôi của hàng đợi SQ. Kernel cũng sử dụng SQE, nó sẽ cập nhật vào đầu của hàng đợi SQ.
- Kernel sẽ tạo một hoặc nhiều CQ entry (CQE) và sẽ cập nhật vào đuôi của hàng đợi CQ. Application cũng sử dụng thằng CQE này và cập nhật từ đầu của hàng đợi CQ.
Systemcall API
io_uring API gồm 3 system call chính bao gồm: io_uring_setup, io_uring_register, io_uring_enter
io_uring_setup
Thiết lập một ngữ cảnh để thực hiện chạy IO bất đồng bộ.
|
|
Lệnh này sẽ tiến hành thiết lập 2 hàng đợi submission queue và completion queue với số lượng các phần tử entries ít nhất. Trả về một file description để thực hiện các hoạt động tiếp theo trên phiên bản io_uring. 2 hàng đợi này được chia sẻ giữa kernel và application, giúp giảm chi phí khi dữ liệu giao tiếp giữa 2 bên (ko cần phải sao chép) khi khởi tạo và thực thi I/O.
Những tham số được sử dụng bởi application để cấu hình cho io_uring instance và kernel sẽ trả lại thông tin về cấu hình đến 2 hàng vòng buffer.
io_uring instance có thể được cấu hình ở 3 chế độ hoạt động chính:
Interrupt drivenMặc định, io_uring instance sẽ được thiết lập để điều khiển IO khi lỗi, IO có thể được gửi bằngio_uring_enter()và được lấy trực tiếp từ completion queue.Polled: thực hiện chế độ chờ I/O hoàn thành. File hệ thống và những thiết bị khối (block device) cần phải được hỗ trợ mới sử dụng tính năng này. Tính năng này giúp giảm thiểu độ trễ khi thực hiện IO, tuy nhiên nó lại tốn nhiều resource của CPU hơn việc thực hiện Interrupt. Hiện nay, tính năng này chỉ thực hiện với những file descriptor được mở kèm với cờO_DIRECT.
Khi đọc hoặc viết vào ngữ cảnh đã thiết lập poll thì ứng dụng phải tiến hành xem tình trạng hoàn thành trên CQ ring bằng lệnhio_uring_enter(). Việc trộn và kết hợp I / O đã được thăm dò và không được thăm dò trên một phiên bản io_uring là ko được phép.Kernel polled: Trong chế độ này, kernel thread được tạo để thăm dò hàng đợi gửi (submission queue). Mộtio_uring instanceđược cấu hình theo cách này cho phép ứng dụng xử lí I/O mà không cần xuống kernel. Bằng việc dùng submisstion queue để điền những SQE mới và kiểm tra tình trạng hoàn thành trên completion queue, ứng dụng có thể submit và lấy kết quả I/O mà không cần thực hiện system call.
Trường hợp kernel rảnh rỗi hơn tổng thời gian người dùng cấu hình, nó sẽ tiếp tục nhàn rỗi đến khi nhận được thông báo từ ứng dụng. Trong trường hợp này, ứng dụng gọi lệnhio_uring_enter()để tiến hành đánh thức kernel.
io_uring_setup()sẽ trả về mộtfd (file descripton), giá trị này được sử dụng chommapđể tạo 2 hàng đợi SQ và CQ, và có thể được sử dụng bởi 2 system callio_uring_register() và io_uring_enter()
io_uring_register
Những file được đăng kí hoặc user buffer chạy IO bất đồng bộ.
|
|
- Được sử dụng cho thực thể io_uring được trỏ bởi
fd. Việc đăng kí này giúp kernel thread
có thời gian tham chiếu tới cấu trúc dữ liệu bên trong kernel liên kết với tệp lâu hơn, hoặc tạo ánh xạ của từng vùng nhớ cụ thể trên ứng dụng với buffer lâu hơn. Chúng ta chỉ cần đăng kí 1 lần thay vì phải thực hiện nhiều lần trong quá trình xử lí, việc này giúp giảm overhead trên IO trong xử lí. - Những buffer được đăng kí sẽ bị khóa trên memory và sẽ bị “tính phí” theo giới hạn
RLIMIT_MEMLOCKcủa người dùng. Thường giới hạn này sẽ là 1GB/buffer. Hiện tại, bộ nhớ đệm phải ẩn danh (ANONYMOUS) và không được sao lưu bằng tệp. - Có thể thiết lập 1 vùng đệm lớn rồi chọn 1 phần nhỏ cho I/O, miễn phần nhỏ đó nằm trong vùng được ánh xạ. Ứng dụng có thể tăng, giảm kích thước hoặc số lượng buffer đã đăng kí bằng cách hủy đăng kí buffer hiện tại và đăng kí buffer mới với lệnh
io_uring_register(). - Một ứng dụng có thể cập nhật động tập các file đã đăng kí mà không cần hủy đăng kí chúng.
- Có thể sử dụng
eventfdđể nhận thông báo về các sự kiện hoàn thành trên phiên bảnio_uring. Nếu đạt được, một eventfd file descriptor có thể được đăng kí thông qua system call này. - Thông tin đăng nhập của ứng dụng đang chạy có thể được đăng kí với
io_uring, nó sẽ trả về một id liên kết với các thông tin đã đăng nhập đó. Các ứng dụng muốn chia sẻ vòng kết nối giữa những người dùng / quy trình riêng biệt có thể chuyển vào id thông tin xác thực này trong trường tính cách SQE. Nếu được đặt, SQE cụ thể đó sẽ được cấp với các thông tin xác thực này.
io_uring_enter
Khởi tạo và hoàn thành I/O bất đồng bộ
io_uring_enter()dùng để khởi tạo và hoàn thành I/O sử dụng hàng đợi submission và completion được thiết lập bởi io_uring_setup(). Một lệnh gọi đơn sẽ bao gồm gửi một I/O mới và đợi phản hồi của lệnh gọi này hoặc tất cả các lệnh gọi trước đó đếnio_uring_enter().
|
|
Trong đó:
fdfile descriptor được return bởiio_uring_setup()to_submitchỉ định số lượng I/O để submit từ submission queue. Nếu được chỉ dẫn nhưu vậy, hệ thống sẽ đợi hoàn thành sự kiệnmin_completetrước khi quay trở lại. Nếu thực thểio_uringđược cấu hình để thăm dò, thìmin_completesẽ có ý nghĩa khác một chút.min_complete: như ở trên đã nói, ngoài ra, nếu nó bằng0ý nói kernel sẽ trả về bất kì sự kiện nào đã được hoàn thành mà không bị chặn. Nếu khác 0, kernel chỉ trả về lập tức sự kiện đang hoàn thành. Nếu không có sự kiện hoàn thành nào khả dụng, thì cuộc gọi sẽ thăm dò ý kiến cho đến khi có một hoặc nhiều sự kiện hoàn thành hoặc cho đến khi quá trình vượt quá phần thời gian của bộ lập lịch của nó. Lưu ý rằng đối với I / O được điều khiển gián đoạn, một ứng dụng có thể kiểm tra hàng đợi hoàn thành để biết sự kiện hoàn thành mà không cần nhập hạt nhân.io_uring_enter()hỗ trợ nhiều phép toán, bao gồm:- Open, close, and stat files
- Read and write into multiple buffers or pre-mapped buffers
- Socket I/O operations
- Synchronize file state
- Giám sát bất đồng bộ một tập file descriptors
- Tạo timeout liên kết tới hoạt động cụ thể trong vòng
- Cố gắng hủy một hoạt động hiện đang bay (thực hiện)
- Tạo I/O chains
- Thực hiện theo thứ tự trong một chuỗi
- Thực thi song song cho nhiều chuỗi
Cơ chế hoạt động
Asynchronous execution
Không phải lúc nào io_uring cũng chạy bất đồng bộ mà nó chỉ chạy khi nó cần. Nguyên nhân là để giảm thiểu tối đa việc gọi io_uring_enter() system call để tăng hiệu suất của chương trình.
Ví dụ ở đoạn code dưới đây (Kernel 5.8)
|
|
Cùng nhìn lại cơ chế làm việc của io_uring
From: https://flattsecurity.medium.com/cve-2021-20226-a-reference-counting-bug-which-leads-to-local-privilege-escalation-in-io-uring-e946bd69177a
- Chúng ta có một cấu trúc
iovecởline 21để định nghĩa một phần tử vector
|
|
Thông thường cấu trúc này được sử dụng như một mảng gồm nhiều phần tử. Mỗi lần chuyển đổi dữ liệu, con trỏ iov_base sẽ trỏ vào vùng đệm để nhận dữ liệu (với lệnh readv) hoặc chuyển dữ liệu (với lệnh writev). Còn phần tử iov_len định nghĩa độ dài tối đa được nhận và được viết trong mỗi lần thực thi. Đoạn code từ line 40-42 để cấp phát cũng như định nghĩa giá trị các phần tử iov_base và iov_len.
- Cấu trúc
io_uring_paramsởline 29dùng để chuyển các tùy chọn đến kernel và từ kernel truyền thông tin về bộ đệm vòng (ring buffer)
|
|
- Code từ
line 29-39dùng để tạo 2 vòng đêm buffer cho SQ và CQ cùng với 1 buffer SQEs để lưu các Submission Entries. - Cấu trúc
timespecởline 44dùng để đặc tả thời gian ở dạng seconds và nanoseconds:
|
|
Ở đây, nó được tạo với 1 sec.
- Cấu trúc
io_uring_sqeởline 37, 46, 52diễn tả cấu trúc của submission queue entry
|
|
Trong đó:
opcode:để đặc tả hoạt động. Ví dụ:readvdùng hằng sốIORING_OP_READVfd:file descriptor của file muốn đọcaddr:được dùng để trỏ đến một mảng các iovec.len: giữ giá trị độ dài của mảng các iovec
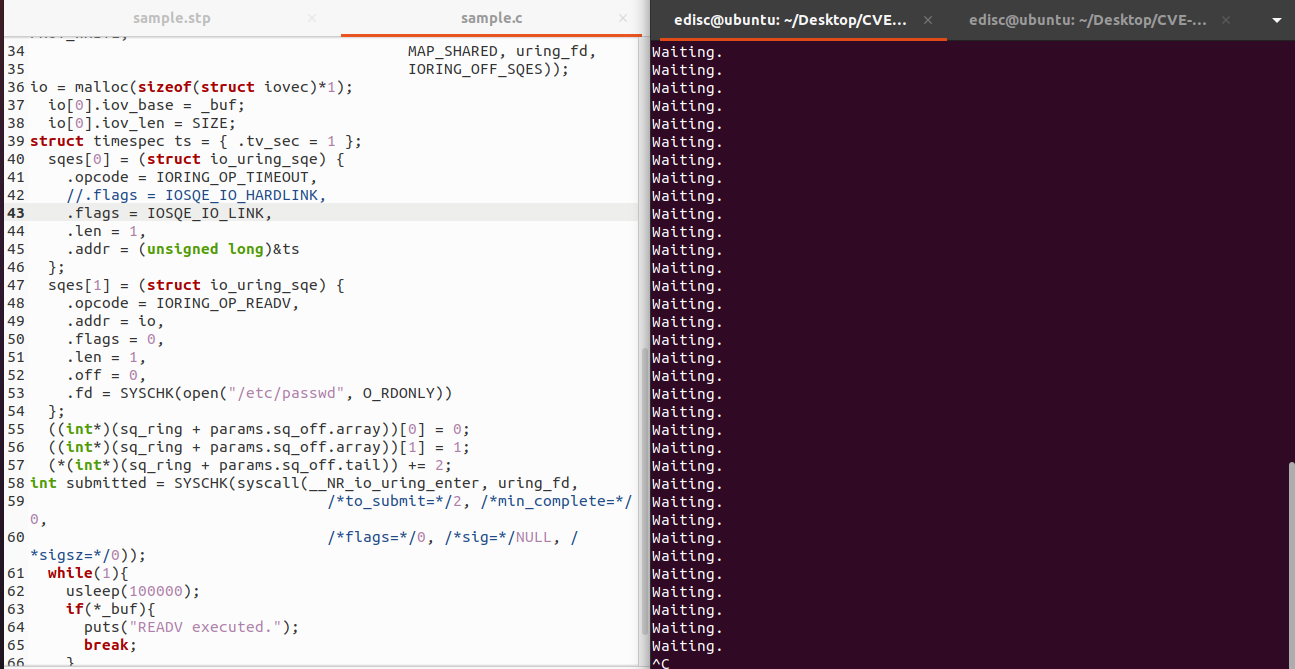
Do đó, đoạn code từ line 52-59 khai báo sử dụng lệnh readv trên file /etc/passwd. Còn từ line 44-51 có sử dụng hằng số IORING_OP_TIMEOUT để chỉ định rằng khi ứng dụng đang sleep thì hoạt động này sẽ được thực hiện.
Cả đoạn code trên, khi thực thi, cứ sau 0.1 seconds sẽ kiểm tra xem liệu readv() đã thực thi xong hay chưa. Và vì ts ta thiết lập nó 1 seconds và truyền vào sqes[0] nên readv() thực thi (sqes[1] thực thi) sẽ sau 1 second. Tuy nhiên, khi thực thi, ta thấy readv() lại thực thi ngay
|
|
Điều này chứng tỏ, hệ thống không chạy bất đồng bộ, hay nói cách khác, nó chỉ chạy khi nó cần thiết, và trường hợp này là không cần thiết, hoạt động của IORING_OP_TIMEOUT đã bị bỏ qua.
Ta sẽ kiểm tra trong trường hợp chương trình sample chạy bất đồng bộ bằng tool systemtap
Theo tác giả thì khi thêm flag IORING_OP_HARDLINK thì chương trình sample.c sẽ tiến hành kiếm tra sau 0.1s in ra dòng chữ waiting và sau 1s lệnh READV sẽ được thực thi, và sẽ in ra READV executed. Tuy nhiên trong quá trình kiểm tra trên ubuntu 20.04, kernel 5.8.0-59-generic thì lại nhận được thông báo IORING_OP_HARDLINK chưa được khai báo. Trong khi IORING_OP_LINK vẫn bình thường.
Một chút về IOSQE_IO_HARDLINK và IOSQE_IO_LINK
Ở trên ta có đề cập tới 2 flag IOSQE_IO_HARDLINK và IOSQE_IO_LINK, ta sẽ tìm hiểu nó là gì.
IOSQE_IO_LINK: cờ này để chỉ định các SQE được chạy trong hàng đợi sẽ phụ thuộc lẫn nhau, phần tử sau đợi phần tử ở trước, giống như trong 1 gia đình, ông bố phải sinh ra rồi thằng con mới được sinh, nếu ông bố sinh thất bại thì thằng con, cháu và cả dòng họ sau này cũng sẽ ra đi theo ông bố. Độ dài của chuỗi sẽ tùy ý, tự mở rộng nếu có thêm SQE vào.IOSQE_IO_HARDLINK: giống như link nhưng nó mạnh hơn. Một số lệnh bị kết thúc do gặp phải lỗi, lúc này kết quả trả về sẽ < 0. Ví dụ, timeout sẽ không có bộ đếm số lần thực hiện, nó sẽ luôn hoàn thành với-ETIMEtrừ khi nó bị hủy. Do đó, nếu dùng cờIOSQE_IO_LINKkhi 1 SQE trả về giá trị nhỏ hơn 0, nó sẽ cắt đứt toàn bộ chuỗi phía sau. Trường hợp chúng ta có dùng lệnh và biết chắc nó sẽ xảy ra lỗi, khi đó,IOSQE_IO_HARDLINKsẽ làm liên kết mạnh hơn mà không bị cắt đứt bởi kết quả trả về ở SQE trước đó. Chú ý rằng liên kết vẫn sẽ bị ngắt nếu lệnh trước đó không gửi và thực hiện được, các liên kết chỉ được phục hồi khi yêu cầu trước đó nhận được phản hồi.
Ta có thể thấy, nguyên lí hoạt động của việc quyết định một tác vụ có chạy được bất đồng bộ hay không như sau:
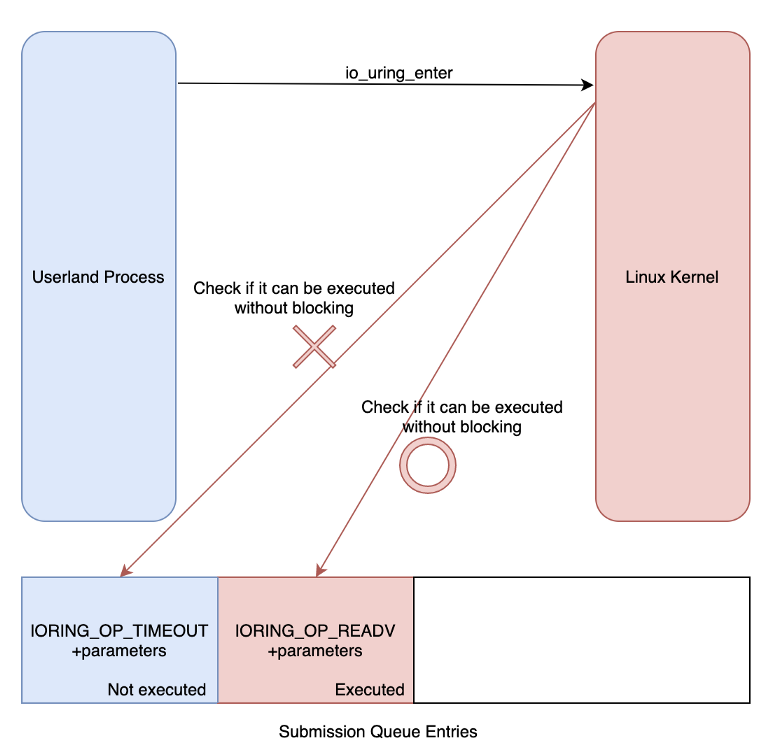
Trong ảnh trên, ta thấy mà process bị chặn lại thì nó sẽ chuyển đến IORING_OP_TIMEOUT và từ đây nó sẽ được chuyển sang kernel thread. Như đã đề cập trước đó, API này nó chỉ chạy bất đồng bộ khi cần nghĩa là sẽ có một số điều kiện nào đó để nó chạy bất đồng bộ. Ví dụ một số trường hợp sau.
- Khi bật cờ yêu cầu buộc phải chạy bất đồng bộ
REQ_F_FORCE_ASYNC
|
|
- Do logic của từng hoạt động riêng, ví dụ như thêm flag
IOCB_NOWAITkhi gọireadv()và trả vềEAGAINkhi muốn dừng.
|
|
code here
Ở đây có cấu trúc io_kiocb phục vụ cho việc đọc file
|
|
Khi giá trị EAGAIN được trả về, process sẽ được đưa vào hàng đợi để chạy bất đồng bộ line 9-23:
|
|
- Khi cờ
IOSQE_IO_LINK | IOSQE_IO_HARDLINKđược sử dụng, thứ tự thực thi sẽ được chỉ định, hoạt động đang thực hiện trước đó sẽ được yêu cầu chuyển sang bất đồng bộ.
|
|
line 12-19 là trường hợp đã tồn tại head request, trong đó: line 12-14 đưa sqe vào đuôi của list. line 16-19 là trường hợp không cờ IOSQE_IO_LINK|IOSQE_IO_HARDLINK không được bật
Nếu không tồn tại head request mà cờ IOSQE_IO_LINK|IOSQE_IO_HARDLINK bật, thì hệ thống sẽ tạo một head mới (line 24), và chuyển sang bất đồng bộ(line 25)
- Nói một cách chính xác, với
IORING_OP_TIMEOUTcó một chút đặc biệt, đó là nó không trả vềEAGAINnhư những minh họa trên, tuy nhiên tác giả nghĩ đây là một ví dụ dễ để hiểu nên ông ta đã quyết định dùng nó để giải thích, minh họa trong blog của mình.
Khi thay thêm.flags = IOSQE_IO_HARDLINKthìIORING_OP_TIMEOUTsẽ được thực thi bởi 1 thread khác, cònIORING_OP_READVsẽ được thực thi sau 1s. Tuy nhiên, tại thời điểm tôi thực hiện trên linux kernel 5.8.0-59-generic, thì lại không tồn tại flagIOSQE_IO_HARDLINK, Tôi vẫn không biết lí do trên là do io_uring đã bỏ nó đi để fix lỗi, hay do trong quá trình cài đặt tôi đã bị thiếu gì đó. Và một điều nữa, tác giả sử dụngsystemstapđể debug rất mượt, còn tôi, trong quá trình follow theo thì lại tốn khá nhiều thời gian cho script này và đến bây giờ vẫn thất bại.

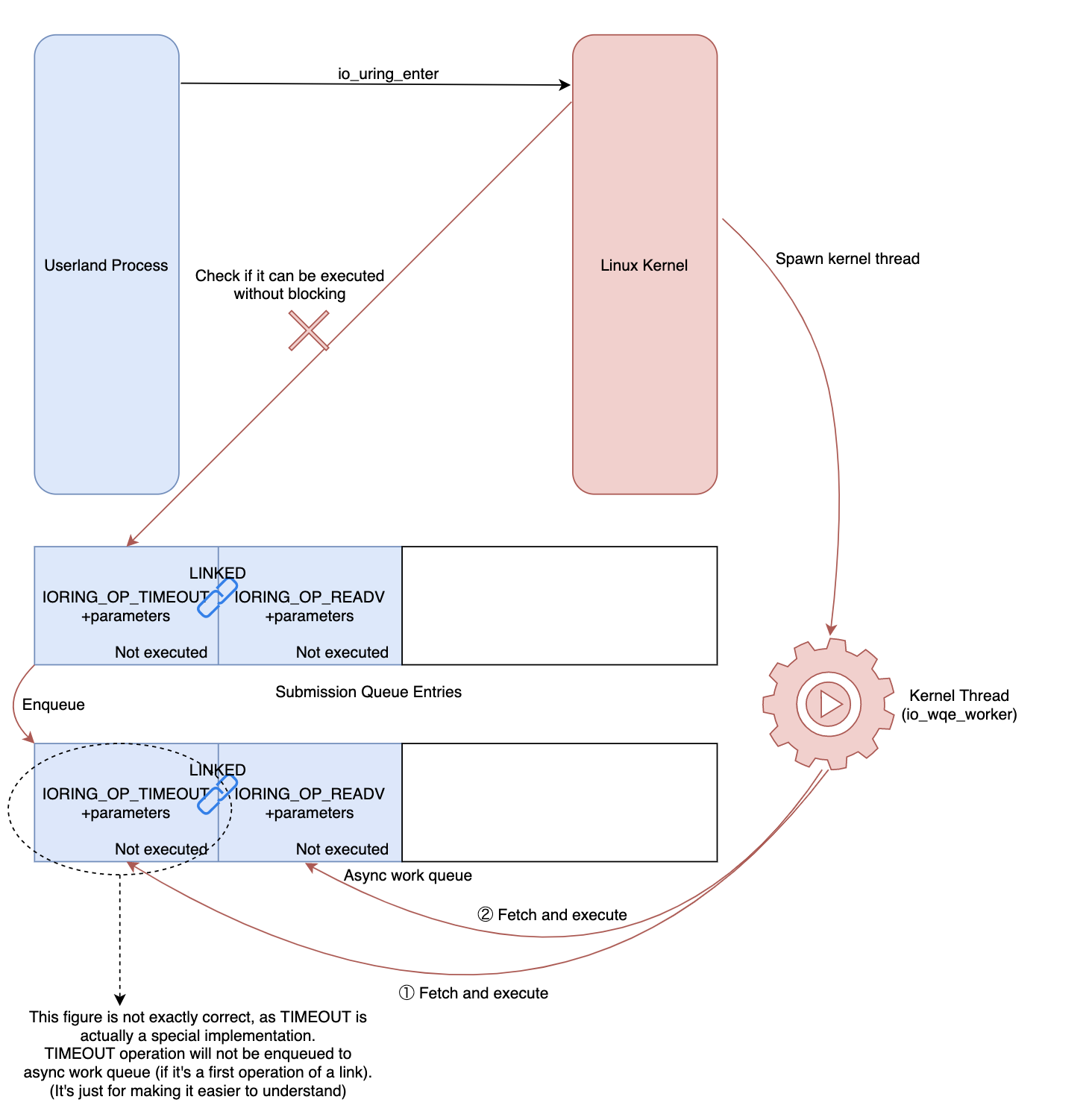
Rõ ràng trên hệ thống chỉ cóIOSQE_IO_LINK, nhưng khi bật flag này, như đã nói ở trước đó, kết quả đạt được là không như mong muốn vì sqe[0] chưa hoàn thành nên sqe[1] (IORING_OP_READV) sẽ không thực thi.
Mặc dù nó không đưa ra kết quả như mong muốn (cần dùngIOSQE_IO_HARDLINK) nhưng khi dùngIOSQE_IO_LINKtừ phía kernel nhìn xuống ta vẫn thấyIORING_OP_READVvàIORING_OP_TIMEOUTvẫn được xử lí như 2 thằng, vàIORING_OP_TIMEOUTđược xem như worker.

Kết quả trên minh họa cho đoạn code để tạo worker từ kernel như sau:
|
|
Khi io_timeout() được gọi, nó sẽ đặt io_timeout_fn() trong handler và bắt đầu bộ đếm thời gian. Sau khi hết thời gian cho phép (timeout) io_timeout_fn() sẽ được gọi để load các hoạt động được kết nối trong hàng đợi để thực thi bất đồng bộ. Tức là IORING_OP_TIMEOUT không có được đặt vào hàng đợi thực thi bất đồng bộ. Tác giả dùng TIMEOUT để giải thích đơn giản vì khi nhắc tới TIMEOUT chúng ta sẽ liên tưởng ngay tới việc luồng thực thi hiện tại sẽ được dừng lại.
Precautions when offloading I/O operations to the Kernel
Chúng ta đã thấy hoạt động bất đồng bộ trên io_uring sẽ được thực hiện bởi worker và chạy dưới dạng Kernel Thread. Tuy nhiên cần có một số lưu ý: Vì nó chạy ở dạng Kernel Thread, nên ngữ cảnh thực thi (execution context) sẽ khác với khi được gọi bởi io_uring. Ở đây, execution context ám chỉ cấu trúc task_struct của process và các thông tin tương ứng của nó. Ví dụ như mm (Manage the virtual memory space of the process), cred (holds UID/GID/Capability), file struct (holds a table for file descriptors)
- Nếu 1 process khi thực thi ở Kernel Thread mà không tham chiếu đúng để cấu trúc trên khi thực hiện systemcall nó có thể trỏ tới bộ nhớ ảo sai, trỏ tới file description table, hoặc đưa ra các hoạt động đặc quyền với Kernel Thread (quyền hạn như root). Trong CVE này, lỗi xảy ra ở đây, người viết tại thời điểm trên quên chuyển cred và làm cho những hoạt động lúc này có thể được thực thi cùng quyền hạn như root. Mặc dù những hoạt động tương đương với
open()tại thời điểm chưa được hiện thực, nên chúng ta không thể đọc file, nhưng chúng ta có thể bắn những thông báo (message) đặc quyền trongsendmsg'svới tùy chọnSCM_CREDENTIALSđể thông báo cho cơ quan có thẩm quyền của người gửi (sender’s authority). Vấn đề này liên quan tới D-Bus. - Do đó, trong
io_uringnhững tham khảo đó được đưa vào worker để worker chia sẻexecution contextbằng cách chuyển qua context của nó trước khi thực thi. - Ví dụ: trong đoạn code sau đây, tại
line 6 và line 9chúng ta có thể thấy tham khảo tớimmvàcredđược đưa vàoreq->work:
|
|
file struct cũng được đưa vào req->work ở đoạn code sau:
|
|
Và trước khi nó chuyển sang thực thi dưới dạng kernel thread, worker sẽ thay thế những tham khảo được truyền vào với nội dung hiện tại của nó.
|
|
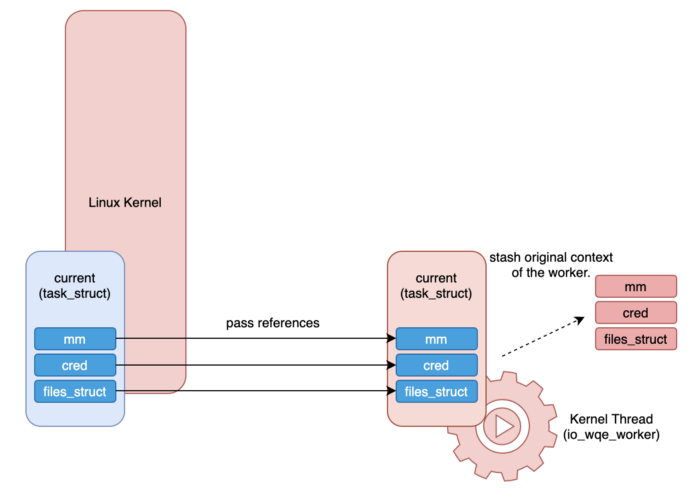
Vulnerability explanation
Reference counter in files_struct structure when sharing with the worker
Trong đoạn code sau đây, worker đang chuyển một tham chiếu đến cấu trúc files_struct của luồng đang thực hiện lệnh gọi hệ thống tới cấu trúc mà worker sẽ tham chiếu sau này mà không cần tăng bộ đếm tham chiếu.
|
|
Bằng cách này, khi vào hàng đợi thực thi bất đồng bộ, tham chiếu tới cấu trúc file được giữ lại đầu tiên từ bộ mô tả tệp được chỉ định
|
|
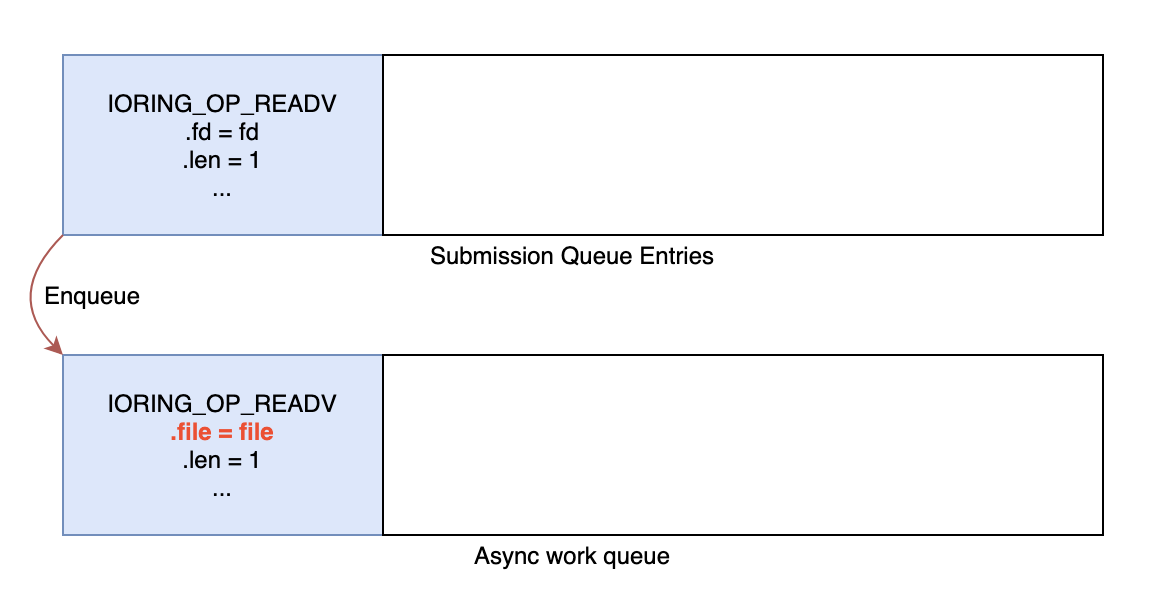
Do đó, worker không cần phải trích xuất nó từ fd hoặc trỏ tới cấu trúc files_struct một lần nữa. Nếu như thế thì việc không tăng bộ đếm tham chiếu tới files_struct không bị ảnh hưởng gì. Nhưng giả định trên không đúng với Linux Kernel 5.5 trở lên bởi vì những system call sẽ ảnh hưởng tới file descriptor table như open/close/accept đã có sẵn trên io_uring, do đó, chúng ta có thể sử dụng để khai thác. Tuy nhiên,
- Chỉ gọi những syscall 1 cách thông thường sẽ chẳng có gì xảy ra khi cấu trúc file_struct đã sẵn sàng, và ko thể tạo ra race condition vì syscall có countermeasures khi xử lí một file bằng nhiều thread.
- Giải phóng
files_structbằng cách thiết lập reference counter bằng 0 => 1 process nào đó có thể dùng nó như là file_struct của nó để thực hiện. Một ví dụ như nhà của bạn mà bạn để bảng “nhà hoang” thì một người nào đó có thể đi vào đó ở, sinh sống. Chúng ta có thể chèn 1 cấu trúc file vào file description table của process mới bằng mở 1 file, nhưng nó sẽ không được reference vì người dùng không sử dụng cố định số lượng file descriptor trong khi lập trình.
Mechanism of reference counter in open/close system call
Để hiểu reference counter trong cấu trúc file hoạt động như thế nào, trước tiên cần hiểu cách thức hoạt động của open/close. Cách thức này sẽ phụ thuộc vào từng file riêng, nhưng có 1 số điểm chung:
Open
- Tạo 1 cấu trúc file và thiết lập reference counter = 1
|
|
- Đăng kí nó vào file description table (fd_install).
|
|
close
1 Xóa trong file description table.
|
|
- Giảm reference counter của cấu trúc
file(fput)
|
|
Ở đây chú ý tới hàm fget()/fput(). Chúng sẽ tăng hoặc giảm reference counter và fput() sẽ giải phóng của cấu trúc file khi reference counter bằng 0. Nếu chúng ta mở file bằng fget() reference counter sẽ không thể bằng 0 ngay cả khi ta đóng file trước khi gọi fput() (bộ đếm sẽ có gía trị là 1 khi chạy lệnh open(), tăng lên 2 khi gọi fget() và nếu lúc này đóng thì nó sẽ giảm xuống còn 1). Do đó, nếu file bị đóng khi đang sử dụng vẫn không có vấn đề gì, vì reference counter vẫn chưa bằng 0 nên cấu trúc file không thể bị giải phóng.
Xét trường hợp gọi mmap, sẽ có vấn đề xảy ra nếu vùng nhớ được giải phóng trước khi gọi munmap, thậm chí là khi gọi close() rồi mà tiếp tục gọi munmap vẫn sẽ bị lỗi. Do đó, fget() được dùng trong mmap để tránh trường hợp bộ nhớ bị giải phóng.
|
|
fdget() which doesn’t change reference counter
2 hàm fdget()/fdput() thường xuyên được sử dụng để tham khảo tới những cấu trúc file được sử dụng nhiều trong system call handlers.
Ví dụ, trong system call read, cấu trúc file được sử dụng giữa fdget()/fdget_pos() và fdput()/fdput_pos() được sử dụng như sau:
|
|
Có một lí do nào đó để hệ thống không cần phải tăng/giảm reference counter của cấu trúc file một cách thường xuyên, có lẽ do ảnh hưởng của bộ nhớ cache(). Do đó, fdget() sẽ không tăng reference counter của cấu trúc file dưới một số điều kiện nhất định. fdget() cuối cùng sẽ gọi hàm __fget_light()
|
|
Trong chương trình đa luồng, file descriptor sẽ được chia sẻ (&file->count >= 2) và cùng 1 file descriptor trỏ đến đến cùng 1 tệp. Trong trường hợp này, những thread khác có gọi close() trong khi read() vẫn đang thực thi. Lúc này, fdget() của read() system call được gọi để giảm reference counter.
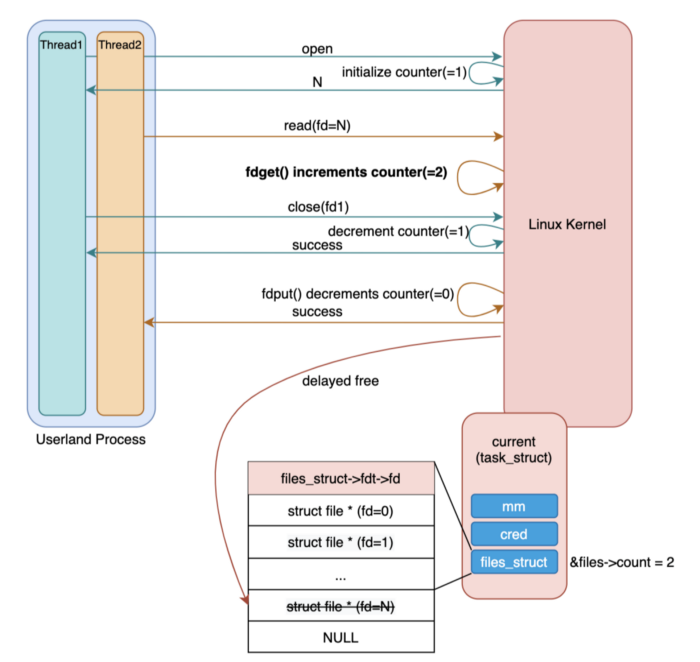
Tuy nhiên, với chương trình chạy đơn luồng khác, tại 1 thời điểm chỉ có 1 thread thực hiện, nên sẽ không thể xảy tra trường hợp trên, do đó, fdget() không cần phải tăng reference counter. Do đó, nó sẽ không tăng reference counter trừ khi file descriptor table được chia sẻ.
Combining vulnerabilities with the fdget() spec
- Lỗ hổng từ việc chuyển 1 tham khảo
file structvào 1 cấu trúc worker trỏ tới mà không tăngreference countervà nếu chương trình gốc là đơn luồng, thì&file->count = 1dù cho file descripton table được chia sẻ. &files->count = 1có nghĩa làfdget()sẽ không tăng reference counter trong cấu trúc file. Do đó, vùng nhớ của cấu trúcfileđược sự dụng bởifdget()có thể bị giải phóng ở 1 thời điểm nào đó.
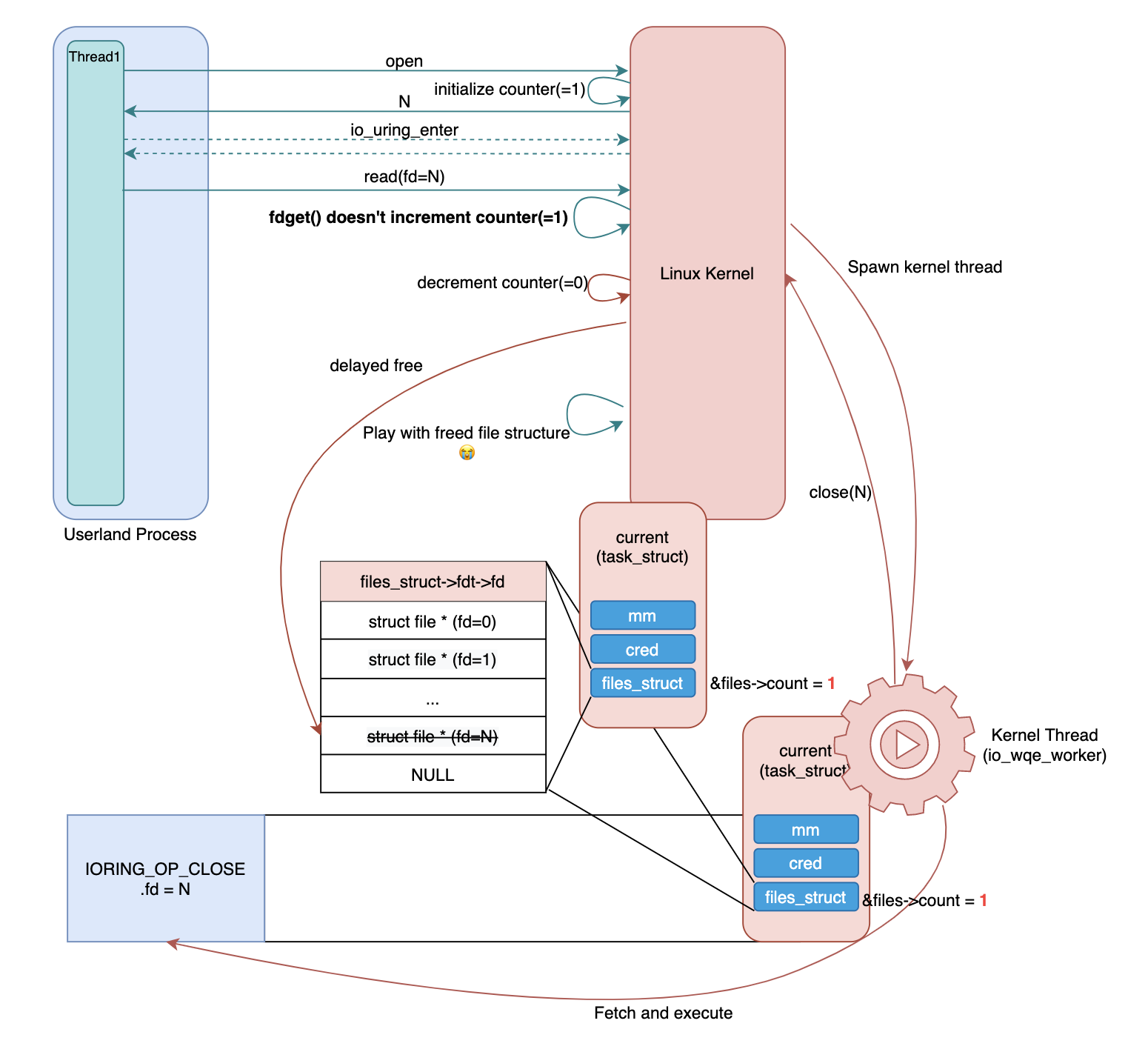
Tóm tắt
Lỗi này như sau:
- AIO worker chia sẻ cấu trúc
file_structvới thread được gọi, và tại thời điểm, reference counter của cấu trúcfiles_structkhông tăng lên. - vì fdget không tăng reference counter của cấu trúc file trong khi reference counter được khởi tạo có giá trị là 1. file được mở bởi
fdget()có thể bị đóng và giải phóng trong worker. - Vì cấu trúc file bị giải phóng nên lỗi UAF có thể xảy ra.